
This article aims to shed light to the highly discussed yet confounding topic in machine learning: hyperparameter tuning. Up to this point, hyperparameter tuning is mostly talked about as a means to get the “best” model, with little being discussed about the how, the what and the why. Building machine learning models like a black box, can either lead to unexplainable results, or inefficient algorithms with exorbitant cost. In order to have a better understanding, we need to talk about how hyperparameter tuning works, what are the available techniques and why we choose an approach over others in certain scenarios. At the end of the article, we present a demonstration using simulated data with 40,000 entries and 100 predictors, comparing performance and cost, between the two main techniques for hyperparameter tuning:
- Grid Search, and
- Randomized Search.
Grid Search requires the user to specify a grid of parameters and it exhaustively searches for all possible combinations within that grid. Say for example, the following grid is given to GridSearchCV for the machine learning model: support vector machine (SVM) classifier with stochastic gradient descent (SGD) training (SGDClassifier).
l1_ratio | 0.2 | 0.5 | 1.0 |
alpha | 0.1 | 0.2 | 0.3 |
The machine learning model will have to fit 9 possible models, with different parameters, to find the one which results in the best scoring metric. The cost of doing a Grid Search increases exponentially with every addition of a new parameter as the Grid Search conducts an exhaustive testing of all possible combinations of parameters. This means that if the search space is huge, doing a Grid Search can get so exorbitantly expensive that the method becomes infeasible.
In this case, a Randomized Search would do the trick. The Randomized Search calls for the user to provide a continuous distribution of numbers for each parameter that needs to be optimized, and a budget of how many parameter settings to test the model with, is provided by the user as well. This means that two things are different between Grid Search and Randomized Search.
| Grid Search | Randomized Search | |
| Cost | Budget is not fixed and increases with search space. | Budget is fixed regardless of search space. |
| Parameters | Parameters need to be chosen wisely, since additional parameters increase cost. | Parameters need not be chosen carefully, since increasing search space, does not affect cost. |
These key differences tell us that one should use Grid Search, if the user possesses prior knowledge about the parameter estimations. In such a case, the user would not be exhaustively testing in a huge search space of parameters, but focus on a smaller search space which is known beforehand. However, if the user is unclear on the suitability of estimated parameters, a Randomized Search would serve the purpose well, with a fixed budget.
It should be clear that the cost in both hyperparameter tuning methods come from the number of sets of parameters that need to be tested in order for the model to work well. Say for instance, GridSearchCV is able to find a model with AUC score of 0.99 after testing 100 sets of parameters, and RandomizedSearchCV finds a model with AUC score of 0.99 only with 20 sets of parameters. It is clear that, in this case, the Randomized Search is superior due to its ability to find a “good” model at a much lower cost. As mentioned earlier, this scenario would likely be due to having a huge search space, with no user prior knowledge of suitable parameter estimates.
Performance and Cost Comparison between Grid Search and Randomized Search.
Extending the theory presented earlier in the post, we would like to see how the accuracy vs cost comparison works out on an actual data set. The data set that we use in this example can be download here. It is a binary classification problem, which is slight imbalanced with 80% outcomes of 0 and 20% with 1. We employ the support vector machine (SVM) classifier with stochastic gradient descent (SGD) training (SGDClassifier) for this problem. The following is the numerical experiment that we will use for each of the hyperparameter tuning method, assuming we have no prior estimates on the suitability of the parameters to be used.
- Data Manipulation: Split the data set into 70% training and 30% as validation/hold-out data.
- Hyperparameter Tuning:
GridSearchCV: use two parameters each with 10 choices such that the resulting grid has 100 candidates.RandomizedSearchCV: provide uniform distributions to two parameters and set the number of candidates tested at 20.
- Model Validation: Test the resulting machine learning model on the validation/hold-out set and compare their AUC scores.
With 5 times less candidates to test for in the Randomized Search, we can expect the Randomized Search to be approximately 5 times less expensive than the Grid Search. The reason we do this is because, we would like to see if it’s possible for Randomized Search to match up to the Grid Search technique, in terms of modeling accuracy, with 5 times less candidates, in the scenario where the user do not have any prior knowledge on parameter estimates.
Data Manipulation
We read the data using pandas and store the predictors and outcomes separately into X and y.
def read_data():
# Read csv file
df = pd.read_csv('../Fullstack/csv/clean_data.csv')
# Transform data into predictors 'X' and outcome 'y'
X = df.drop('y', axis=1).values
y = df['y'].values
return df, X, y
The 70% training set and 30% test set is then separated using train_test_split with a constant random seed, such that the results are reproducible.
def split_data(X, y):
from sklearn.model_selection import train_test_split
# Split dataset into 70% train, 30% test
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
stratify=y,
random_state=SEED)
return X_train, X_test, y_train, y_test
Hyperparameter Tuning
The hyperparameter tuning is first instantiated by the following function to create the object. The function input type_of_search is a python list where the first entry is specifies type of hyperparameter tuning method (“GridSearch” or “RandomizedSearch”), and the second entry is an integer which specifies number of sets of parameters (“100” for GridSearch and “20” for RandomizedSearch”). In this problem, the two parameters we will be tuning are the l1_ratio (an Elastic Net mixing parameter ranging [0, 1], and alpha (a constant used for in computing learning rate). The scoring criterion is set as the AUC score.
def initiate_hyperparameter_search(type_of_search):
import scipy.stats as stats
from sklearn.utils.fixes import loguniform
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# Instantiate support vector machine classifier 'svc'
svc = SGDClassifier(loss='log', random_state=SEED)
if type_of_search[0] == 'GridSearch':
# Define the grid of hyperparameters 'params_svc'
params_svc = {'l1_ratio': np.linspace(0.0, 1.0, 10),
'alpha': np.linspace(1e-4, 1.0, 10)}
# Instantiate a grid search object 'search_svc'
search_svc = GridSearchCV(estimator=svc,
param_grid=params_svc,
scoring='roc_auc',
n_jobs=-1)
elif type_of_search[0] == 'RandomizedSearch':
# Define the grid of hyperparameters 'params_svc'
params_svc = {'l1_ratio': stats.uniform(0.0, 1.0),
'alpha': loguniform(1e-4, 1.0)}
# Instantiate a randomized search object 'search_svc'
search_svc = RandomizedSearchCV(estimator=svc,
param_distributions=params_svc,
scoring='roc_auc',
n_iter=type_of_search[1],
random_state=SEED,
n_jobs=-1)
return search_svc
linspace is chosen to simulate a scenario where user has no prior useful knowledge on the estimation of the parameters, and hence equally spaced numbers are used. After creating the search object, we conduct the hyperparameter search by fitting the train data to the model.
def hyperparameter_search(search_svc, X_train, y_train, type_of_search):
from time import time
# start timer
start = time()
# Fit search_svc to the training set
search_svc.fit(X_train, y_train)
# print time taken
print("%sCV took %.2f seconds for %d candidates"
" parameter settings." %(type_of_search[0], time() - start, type_of_search[1]))
# Extract best model
best_model = search_svc.best_estimator_
print('Best AUC score: %0.8f'%search_svc.best_score_)
print('Best parameters: ', search_svc.best_params_)
return best_model, search_svc.best_score_
We also record the time taken for the hyperparameter search to find the most optimal model.
Model Validation
After the most optimal model is chosen by Grid Search and Randomized Search, the models are tested against the validation/hold-out data set and checked for their accuracy. Below are the ROC curves, AUC scores and cost evaluation for each of the two hyperparameter tuning methods.
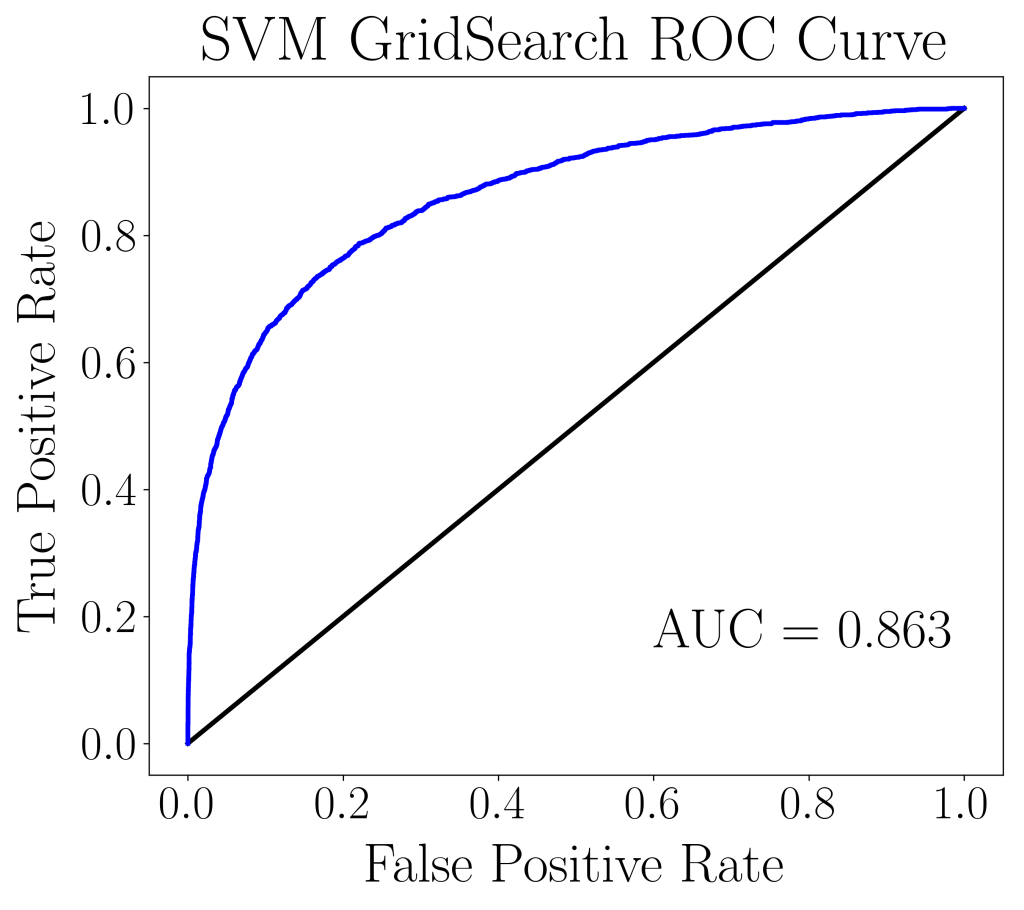
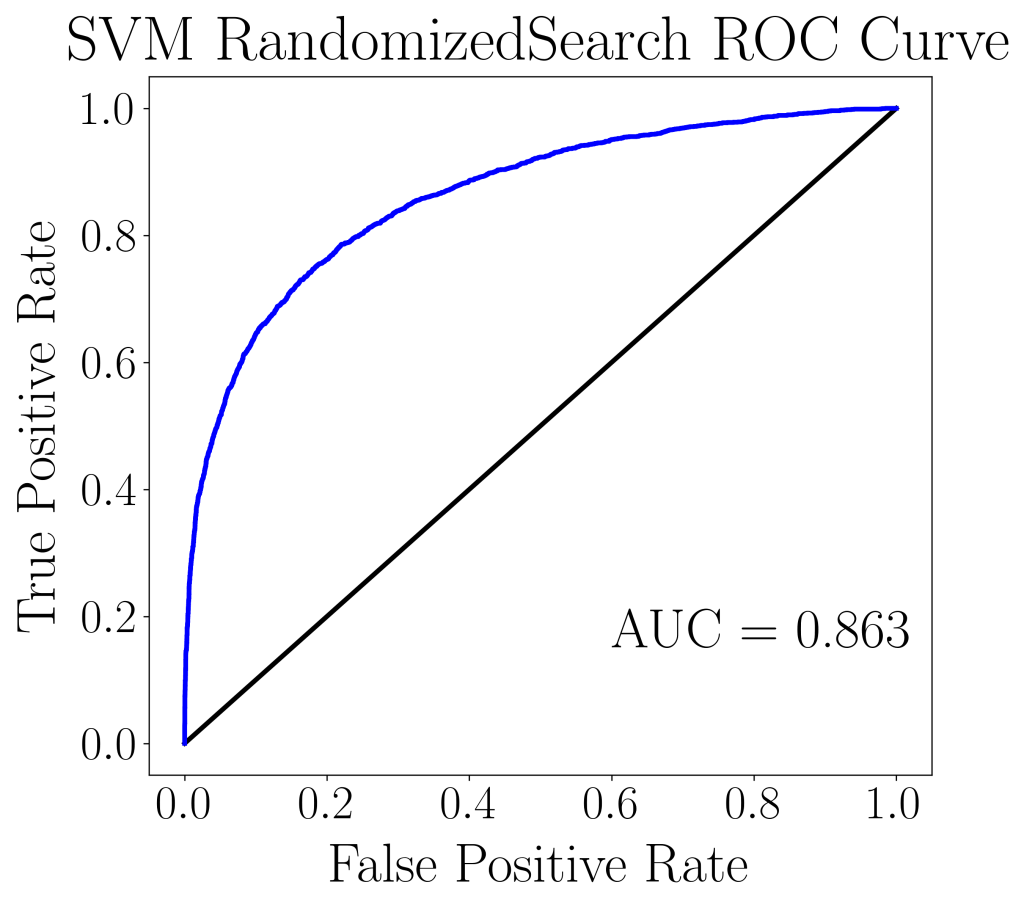
It is clear that both AUC scores as well as ROC curves on the validation/hold-out set are the same (up to the third decimal place). However, the Randomized Search used only 1/5 the number of sets of parameters and hence approximately 1/5 of the cost. The 5-fold CV AUC score for the Randomized Search on the training set is 0.876 and on the test set is 0.863. For the Grid Search, the AUC score on training set is 0.877 and on the test set it’s 0.863. Since both models have approximately the same AUC score between their train and test sets, both models are deemed well-fitted with no signs of over- or under-fitting.
| Grid Search | Randomized Search | |
| Time taken | 98.06 s | 25.06 s |
In summary, we see that Randomized Search can be advantageous in scenarios where the user doesn’t have an intelligent guess on suitable parameters to be chosen. Randomized Search produced approximately the same AUC score using 5 times less resources, simply because we understand the how, the what and the why of hyperparameter tuning!

Pingback: Sentiment Analysis: IMDB movie review classification using NLTK and Random Forest Classifier – Data Bay Today